Table Of Content
Week one would be replication one, week two would be replication two and week three would be replication three. The test on the block factor is typically not of interest except to confirm that you used a good blocking factor. In studies involving human subjects, we often use gender and age classes as the blocking factors. We could simply divide our subjects into age classes, however this does not consider gender. Therefore we partition our subjects by gender and from there into age classes. Thus we have a block of subjects that is defined by the combination of factors, gender and age class.
Continuous Variables and
Assume that we can divide our experimental units into \(r\) groups, also known asblocks, containing \(g\) experimental units each.Think for example of an agricultural experiment at \(r\) different locationshaving \(g\) different plots of land each. Hence, a block is given by a locationand an experimental unit by a plot of land. In the introductory example, a blockwas given by an individual subject.
Nuisance variables
And within each of the two blocks, we can randomly assign the patients to either the diet pill (treatment) or placebo pill (control). By blocking on sex, this source of variability is controlled, therefore, leading to greater interpretation of how the diet pills affect weight loss. Once the data are recorded, we are interested in quantifying how ‘good’ the blocking performed in the experiment. This information would allow us to better predict the expected residual variance for a power analysis of our next experiment and to determine if we should continue using the blocking factor.

Table of Contents
In this experiment, we are interested in contrasting the plates on the same patients, not the patients themselves. The ten plates are then the treatment factor levels, and each patient is a block to which we assign plates. The previous examples includedtwo groups of subjects where thetreatment was assumed to be the only difference, and where all samplescould be processed at the same time.
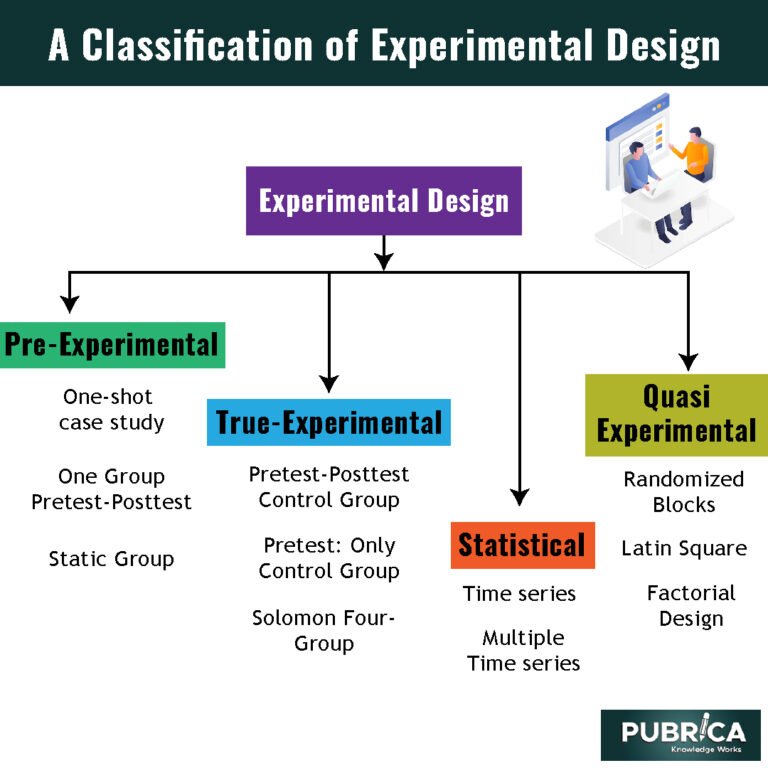
After that, the observational units from each block are evenly allocated into treatment groups in a way such that each treatment group is allocated similar numbers of observational units from each block. So what types of variables might you need to balance across your treatment groups? Blocking is most commonly used when you have at least one nuisance variable. A nuisance variable is an extraneous variable that is known to affect your outcome variable that you cannot otherwise control for in your experiment design. If nuisance variables are not evenly balanced across your treatment groups then it can be difficult to determine whether a difference in the outcome variable across treatment groups is due to the treatment or the nuisance variable. By extension, note that the trials for any K-factor randomized block design are simply the cell indices of a k dimensional matrix.
The ANOVA for Randomized Complete Block Design (RCBD)
A balanced incomplete block design allows blocking of simple treatment structures if only a subset of treatments can be accommodated in each block. The latin square design requires identical number of levels for the row and column factors. We can use two blocking factors with a balanced incomplete block design to reduce the required number of levels for one of the two blocking factors. These designs are called Youden squares and only use a fraction of the treatment levels in each column (resp. row) and the full set of treatments in each row (resp. column). The idea was first proposed by Youden for studying inoculation of tobacco plants against the mosaic virus (Youden 1937), and his experiment layout is shown in Figure 7.16.
We will talk about treatment factors, which we are interested in, and blocking factors, which we are not interested in. We will try to account for these nuisance factors in our model and analysis. Blocking factors and nuisance factors provide the mechanism for explaining and controlling variation among the experimental units from sources that are not of interest to you and therefore are part of the error or noise aspect of the analysis. An attractive alternative is the linear mixed model, which explicitly considers the different random factors for estimating variance components and parameters of the linear model in Equation (7.1). Linear mixed models offer a very general and powerful extension to linear regression and analysis of variance, but their general theory and estimation are beyond the scope of this book. For our purposes, we only need a small fraction of their possibilities and we use the lmer() function from package lme4 for all our calculations.
An assumption that we make when using a Latin square design is that the three factors (treatments, and two nuisance factors) do not interact. If this assumption is violated, the Latin Square design error term will be inflated. Another way to look at these residuals is to plot the residuals against the two factors.

Note that if the groups were reversedin the ordered sample allocation scheme, the group mean differencewould have been exaggerated instead. In addition you can open this Minitab project file 2-k-confound-ABC.mpx and review the steps leading to the output. The response variable Y is random data simply to illustrate the analysis. Notice that unlike for the RCBD, the reduced normal equations for a BIBD do not correspond to the equations for a CRD. Although the first term in \(q_i\) is the sum of the responses for the \(j\)th treatment (mirroring the CRD), the second term is no longer the overall sum (or average) of the responses. In fact, for \(q_j\) this second term is an adjusted total, just involving observations from those blocks that contain treatment \(j\).
The foundational concepts of blocking date back to the early 20th century with statisticians like Ronald A. Fisher. His work in developing analysis of variance (ANOVA) set the groundwork for grouping experimental units to control for extraneous variables. An example layout of this design is shown in Figure 7.14A, where the two blocking factors are given as rows and columns.
Experimental Economics - Econlib
Experimental Economics.
Posted: Sun, 17 Jun 2018 00:29:43 GMT [source]
For example, suppose researchers want to understand the effect that a new diet has on weight less. The explanatory variable is the new diet and the response variable is the amount of weight loss. Four possible (ordered) batch compositionswith four groups anda batch size of three. Each celltype occurs in a batch alongside each other cell type exactly twice.
The dependence of the block- and treatment factors must be considered for fixed block effects. The correct model specification contains the blocking factor before the treatment factor in the formula, and is y~block+drug for our example. This model adjusts treatments for blocks and the analysis is identical to an intra-block analysis for random block factors.
Otherwise, block-to-block differences may bias treatment comparisons and/or inflate our estimate of the background variability and hence reduce our ability to detect important treatment effects. To address nuisance variables, researchers can employ different methods such as blocking or randomization. Blocking involves grouping experimental units based on levels of the nuisance variable to control for its influence. Randomization helps distribute the effects of nuisance variables evenly across treatment groups.








No comments:
Post a Comment